One of the things I like about DDD is that it has solutions for a wide variety of problems. One of those is how to handle legacy software, and specifically how to move away from those. There’s a passage in the book about this subject, as well as some additional material online.
This year I’m planning to apply some of these principles and techniques to a project we’ve developed and use internally at Infi: our time tracker. This tool has been under development for 8+ years now, and throughout the years it’s become ever harder to add new functionality. There are various reasons for this, such as outdated technology, a missing vision on the design and the software trying to solve many separate problems with just one model. So there’s been pressure to replace this system for a while now, and doing so via DDD-practices seems both natural and fun.
This is going to be more of a journey than a project, so I’ll try to keep you updated during the year.
DDD style legacy replacement
The DDD style approach to moving away from legacy is to first and foremost focus on the core domain. We shouldn’t try to redesign the whole system at once, or try to refactor ourselves out of the mess, since that hardly ever works. Besides, there is probably a lot of value hidden in the current non-core legacy systems, and it doesn’t make sense to rewrite that since it’s been working more or less fine for years and we don’t actually need new features in these areas.
Instead, we should identify the actual reasons why we want to move away from the legacy system, and what value it’s going to bring us when doing so. More often than not, the reason will be deeply rooted in the core domain: maybe we’re having problems delivering new features due to an inappropriate model, maybe the code is just really bad, etc. Whatever the reason, the current system is holding back development in the core domain, and that’s hurting the business.
So how do we approach this? The aforementioned resources provide a couple of strategies, and they all revolve around a basic idea: create a nice clean, isolated environment for developing a new bounded context. This new bounded context won’t be encumbered by existing software or models, and we can develop a new model that addresses the problems we’d like solve in our core domain.
The goal
So what are our reasons for wanting replace our current application? Well, you can probably imagine that time tracking is very important to us since this is what we use to bill our clients. Also, we use it internally to measure all sorts of stuff and make management decisions based on that data. These issues make time tracking a key process in our organization. To be fair, it’s not mission critical, but still important enough to consider Core Domain.
For our goals, time tracking is only effective if it’s both accurate and entered timely. I think the number one way to stimulate this is making tracking your time as easy and convenient as possible. I think we can improve on this by creating a model of the way that people actually spend in our company. By having deep knowledge about the way the time is spent, I envision the model being able to, for example, provide context-sensitive suggestions or notify people at sensible times that time-entry is due. Having these kind of features would make tracking your time a little less of a burden.
The plan
Let’s look at our current context map:
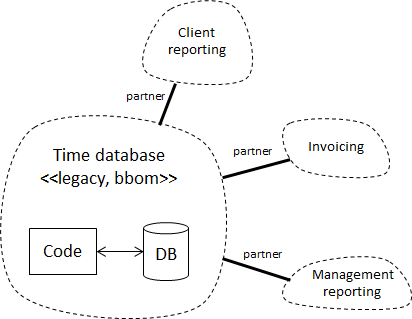
There are currently 4 Bounded Contexts
- Time database. This is the current application. I’ve declared it a big ball of mud since I don’t think there’s a consistent model hidden in there, and frankly I don’t care. This application is currently used for entering your times, generating exports, managing users, etc.
- Client reporting. Client reporting is concerned with regularly giving updates to our clients about how we spend our time. It gets its data from TTA, but uses a different model for the actual reporting step, which is why it’s a separate BC. Most of the work with this model is manual, in Excel.
- Invoicing. While the TTA currently has functionality for generating invoices, we don’t directly use that for sending invoices to our customers. We use data from the TTA, but then model that differently in this context. Again, this is mostly manual work.
- Management reporting. This is what we use to make week-to-week operational decisions, and uses yet another model. This is actually an API that directly queries the TTA database.
I’m not planning on replacing the entire existing application for now, just the parts that have to do with time entry. Reporting, for example, is out of scope.
We see all BCs partners because functions are required to successfully run the company. It’s probably possible to unify the “satellite” models, but we don’t care about that now since we want to focus on the actual core domain of actually doing the time tracking.
For the new system, we’re going to try the “Bubble Context with an ACL-backed repository” strategy, and hope we can later evolve it to one of the other strategies. The destination context map will look like this:
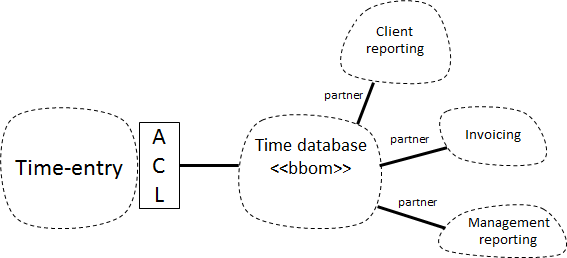
The new BC will contain all the new code: an implementation of the model as well as a new GUI. For a lack of a better name I’ve called it Time-entry for now.
A final twist
Just to make things more interesting, I’m planning on doing the new code in Clojure. There are a couple of reasons for this:
- I just like learning new stuff, and Clojure is new for me.
- I’ve been encountering Lisps more and more over the last couple of years, and people that I highly respect often speak about Lisps in high regard. So it’s about time I figure out what all the fuss is about.
- I’d like to try something outside of .NET, for numerous reasons.
- Lisps are known for their ability to nicely do DSLs, and that seems a good fit for DDD.
- I want to see how DDD patterns map to a more functional language, and specifically what impact that has on modeling.
- I wonder how interactive programming (with a REPL) works in real-life
My experience with Clojure thus far has been some toy projects and I read the Joy of Clojure, but that’s about it. So expect me to make a lot of rookie mistakes, and please tell me when I do 🙂
Next steps
All the new code will be open source and on Github. I probably won’t be able to open source the code for the original application, but I hope I can publish enough to be able to run the ACL. This should be enough to get the entire application running. I hope to get the first code out in a couple of weeks.