While Atom is often associated with things like blogs or news feeds, it turns out it’s also an excellent vehicle for integrating application data across your systems. At Infi we’re using this technique for several integration scenario’s for our customers, and it’s quickly becoming a preferred way of solving this kind of problem.
This post assumes a basic understanding of Atom (though you can probably follow it if you don’t). If you need to brush up your knowledge, you can read a basic introduction here.
Context
We often have a situation where a subset of users manage data that is exposed to a much larger set of different users. For example, we might have a website that deals with selling used cars from car dealers, where the car dealers manage the car data, such as pictures, descriptions, etc. This data is then viewed by a large group of users on the website. One of our customers has a similar model, though in a different domain.
As this customer has grown, more and more additional systems needed access to this data, such as several websites, external API’s and an e-mail marketing system. We used to do these integrations on an ad-hoc basis, using a custom-built solution for every integration (e.g. database integration, RPC, XML feeds). As you can imagine, this situation was becoming an increasing point of pain since it doesn’t really scale well in a couple of dimensions, such as performance, documentation, reward/effort, etc. The situation looked more or less like this:
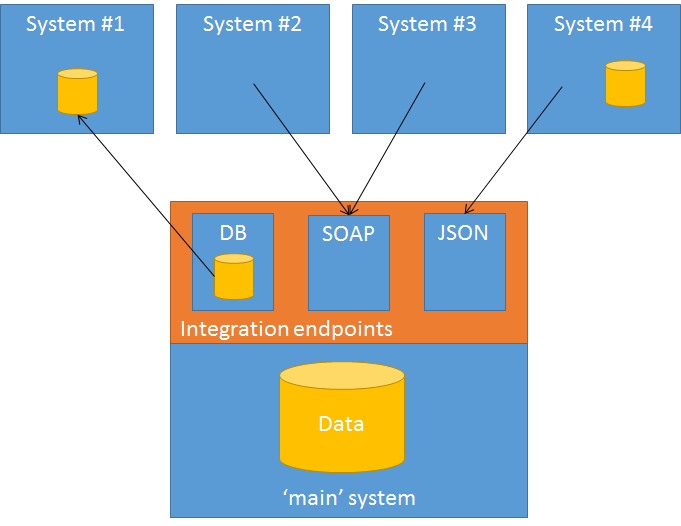
Requirements
To remove some of this pain we decided on building something new, specifically having the following requirements:
Good performance. This means 2 things: first, we want low latency responses on requests on our integration system. Second, we don’t want high loads on the integration solution pulling down other parts of our system.
Low latency updates. It’s OK for the data to be eventual consistent, but under normal conditions we want propagation times to be low, say on the order of several minutes or less.
No temporal coupling. Consumers shouldn’t be temporally coupled to the integration system. This means they should be able to continue doing their work even when the integration endpoint is unavailable.
Support multiple logical consumers. All (new) integrations should be done through the new system, such that we don’t need to do any modifications for specific consumers.
Ease of integration. It should be easy for consumers to integrate with this new system. Ideally, we should only have to write and maintain documentation on the domain-specific parts and nothing else.
It turns out we can address all these requirements by combining two ideas: snapshotting the data on mutations and consumer-driven pub/sub with Atom feeds.
Solution
The core idea is that whenever an update on a piece of data occurs, we snapshot it, and then post it to an append-only Atom feed:
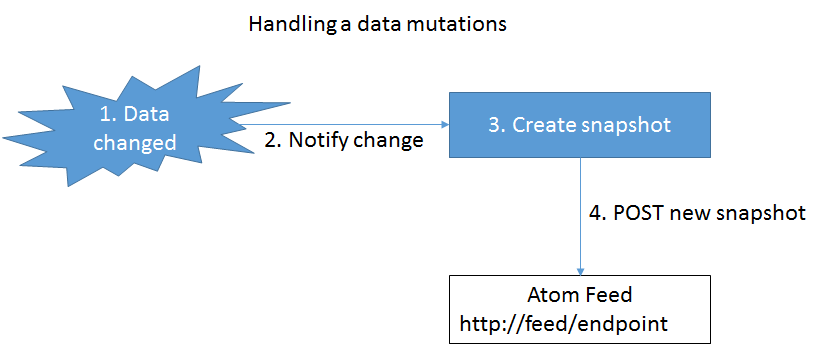
This way we essentially build up a history of all the mutations inside the feed. The second part of the solution comes from organizing (paging) the feed in a specific way (this builds on top of the Feed Paging and Archiving RFC):
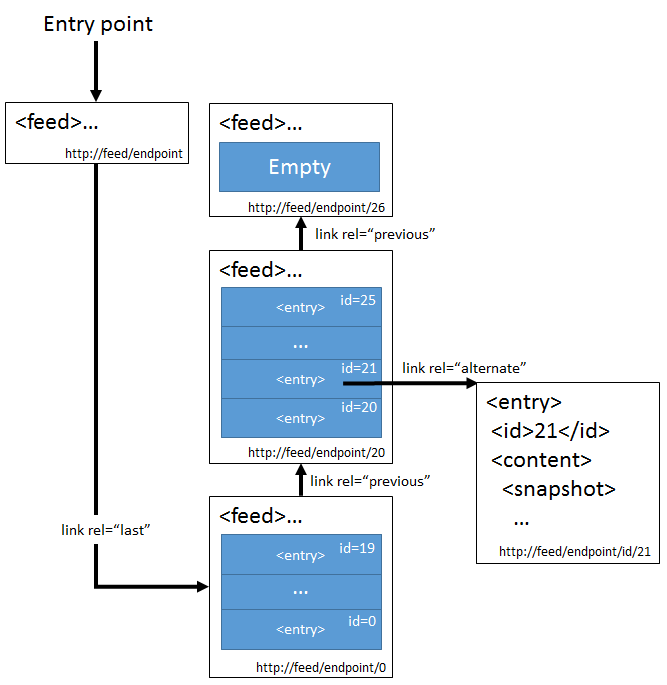
In this case we divide the snapshots into pages of 20 entries each.
The value in this structure is that only the root and the currently ‘active’ pages (i.e. not completely filled pages) have dynamic content. All the other resources/URLs are completely static, making them indefinitely cacheable. In general, most of the pages will be full, so almost everything will be cacheable. This means we can easily scale out using nginx or any other caching HTTP proxy.
Consuming the feed
From a consumer point of view you’re gonna maintain your own copy of the data and use that to serve your needs. You keep this data up to date by chasing the ‘head’ of the feed. This is done by continuously following the rel=”previous” link in the feed documents. Once you read the head of the feed (indicated by no entries, and a missing link rel=”previous”) you keep polling on that URL until a new entry appears.
Evaluating the solution
To see how this solution fulfills our requirements, let’s revisit them:
Good performance
- Since data is snapshotted, we don’t need to do expensive querying on our transaction-system database. This allows for both quick responses to in the integration system as well as isolation of our transactional system.
- Because almost everything is cacheable, you can easily scale out and provide low-latency responses.
Low latency updates
- The detection of changes to the data is event-based instead of some sort of large batch process to detect changes. This allows the data to flow quickly through the system and appear in the feed. Polling the head of the feed is not expensive and can therefore be done on minute or even second basis, so the clients themselves will also be able to notice the updates quickly.
No temporal coupling
- First of all, the consumers are decoupled from the integration system because they have their own copy of the data so they don’t have to query the feed in real-time to serve their needs. Secondly, the integration system itself is also not coupled to the system containing the original data, since the snapshots are stored in the Atom feed.
Support multiple logical consumers
- Multiple logical consumers are trivially supported by handing out the URL to the feed endpoint.
- One problem is different consumers requiring different parts of the data. Currently, we’ve solved this by always serving the union of all required data pieces to all the consumers. This isn’t exactly elegant, but it works (though we sometimes need to add fields). A better solution would be for clients to send an Accept header containing a mediatype that identifies the specific representation of the data they want.
- We also built in rudimentary authentication based on pre-shared keys and HTTP basic authentication.
Ease of integration
- This is where the whole Atom thing comes in. Since both Atom and paging techniques are standard, we only need to document the structure of our own data. From a client point of view, they can use any standard Atom reader to process the data.
- To make things even more easy to integrate, we also created a custom JSON representation for Atom. This is useful for consumers on platforms that don’t have strong XML support.
Conclusion
As you can see, all our requirements are met by this solution. In practice, it also works very well. We’ve been able to reduce loads on our systems, get data quicker into other systems, and both for us and our partners it’s easier to implement integrations. We started out doing this for just one type of data (property information), but quickly implemented it for other types of data as well.
One of the challenges is pick the right level of granularity for the feeds. Pick the granularity too narrow, and it becomes harder for a client to consume (needs to keep track of lots of feeds). Pick it too wide, and there will be a lot of updates containing little change. In our cases, common sense and some basic analysis of how many updates were expected worked out fine.
The main drawbacks we encounter are twofold. First, people not familiar with Atom and the paging standards sometimes had problems working with the feed structure. Especially when there’s no platform support for Atom or even basic XML, we sometimes still have to help out. Second, for some integrations maintaining a copy of the data on the consumer side proved to be a bit too much (or not even possible). For these situations we actually built a consumer of our own, which served data to these thinner clients.
Credits
The ideas in this post are not new. We were particularly inspired by EventStore, which also provides an Atom based API for exposing its event streams.