The first step in my effort to freshen up our time tracker using DDD & Clojure has been finding a way to structure my code. Since I don’t have that much Clojure experience yet, I decided to take the DDD layered architecture and port it as directly as possible. This probably isn’t really idiomatic Clojure, but it gives me a familiar start. This post should be regarded as such, my first try. If you know better ways, don’t hesitate to let me know.
The architecture
As a picture is worth a thousend words:
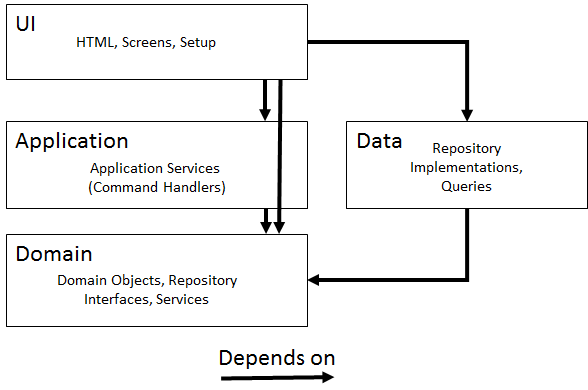
This architecture is mostly the same as the one advocated in the DDD Blue Book, except that the Domain Layer does not depend on any data-related infrastructure and there’s a little CQRS mixed in. I think this is mostly standard these days. In this design, the application layer is responsible for transaction management. The ‘Setup’ part of the UI layer means setting up things like dependency injection.
In this post I’ll focus on the interaction between application services, domain objects, repositories and the data layer. I’ll blog about other parts (such as validation) in later posts.
The domain
Unfortunately, I’m not able to release the code for the time tracker just yet (due to some issues with the legacy code). So for this post I’ll use an example domain with curently just one entity… Cargo 🙂 The Cargo currently has one operation: being booked onto a Voyage.
The approach
Let’s start with the Domain Layer. Here, we need to define an “object” and an “interface”: the Cargo and CargoRepository respectively.
Cargo entity
The Cargo entity is implemented as a simple record containing the fields cargo-id, size and voyage-id. I’ve defined a constructor create-new-voyage which does its input validations use pre-conditions.
There’s one domain operation, book-onto-voyage which books the cargo on a voyage. For now, the requirement is that it can’t already be booked on another Voyage. (Remember this post is about overall architecture, not the domain logic itself, which is for a next post).
Furthermore, there is a method for setting the the cargo-id since we rely on the data store to generate it for us, which means we don’t have it yet when creating a new cargo.
Here’s the code:
Cargo Repository
The Cargo Repository consists of 2 parts: the interface which lives in the domain layer, and the implementation which lives in the data layer. The interface is very simple and implemented using a Clojure protocol. It has 3 functions, -find, -add! and -update!.
A note about concurrency: -find returns both the cargo entity and the version as it exists in the database in a map: {:version a-version :cargo the-cargo}. When doing an -update! you need to pass in the version so you can do your optimistic concurrency check. (I’m thinking of returning a vector [version cargo] instead of a map because destructuring the map every time hurts readability in client code, I think.)
Furthermore, I’ve defined convenience methods find, add! and update!, which are globally reachable and rely on a call to set-implementation! when setting up the application. This is to avoid needing to pass (read: dependency inject) the correct repository implementation along the stack. This is probably a bit controversial (global state, pure functions, etc), and I look forward to exploring and hearing about alternatives.
Cargo repository MySQL implementation
I’m using MySQL as the data store, and clojure.java.jdbc for interaction with it. The cargoes are mapped to one table, surprisingly called cargoes. I don’t think there’s anything particular to the implementation, so here it goes:
The final parts are the Application Services and the UI.
The Application Service
I never have good naming conventions (or, almost equivalently, partitioning criteria) for application services. So I’ve just put it in a namespace called application-service, containing functions for all domain operations. The operations can be taken directly from the Cargo entity: creating a new one, and booking it onto a voyage. I use the apply construct to invoke the entity functions to avoid repeating all parameters.
Code:
The UI The tests
To not make this post any longer than it already is I’m not going to show a full UI, but a couple of tests exercising the Application Service instead. This won’t show how to do queries for screens, but for now just assume that I more or less directly query the database for those.
There isn’t much to tell about the tests. If you are not that familiar with Clojure, look for the lines starting with deftest, they define the actual tests. The tests show how to use the application service API to handle commands. They test the end result of the commands by fetching the cargo from the repository and checking its state. I use the MySQL implementation for the database, since I already have it and it performs fine (for now).
Conclusion
The code in this post is pretty much a one-to-one mapping from an OO kind of language to Clojure, which is probably not ideal. Yet, I haven’t been able to find some good resources on how you would structure a business application in a more Clojure idiomatic way, so this will have to do. Nevertheless, I still like the structure I have now. I think it’s pretty clean and I don’t see any big problems (yet). I look forward to exploring more alternatives in the next couple of months, and I’ll keep you updated.