A lot of people are applying dependency injection (DI) in their software designs. As anything, DI has its proponents and opponents but I believe that given the right context it can actually help your software design by making dependencies more explicit and better testable.
A lot of implementations of DI I encounter have a problem though: they have the actual dependency running in the wrong way. In the case of business software, for example, this would be the business layer depending on the the data layer instead of the other way around. This can cause some pretty significant problems downstream.
In this post I’ll review the basics of dependency injection, dependency inversion and the problems that occur when the dependency is running the wrong way.
Injecting data access code in business apps
One of the contexts in which I’ve had success applying DI is data access in business software. In order to keep our business rule tests run fast enough we need an in-memory data source instead of a disk-based one, since those are usually (still) not fast enough. You usually end up with something like this:
interface DataAccess {
Record GetRecordById(int id);
void Save(Record record);
}
class Application {
DataAccess _access;
public Application(DataAccess access) {
_access = access;
}
public void UpdateRecordName(int id, string newName) {
var rec = _access.GetRecordById(id);
rec.Name = newName;
_access.Save(rec);
}
}
In our tests, we then initialize Application with some kind of InMemoryDataAccess implementation and our production system we uses a PersistentDataAccess. All pretty standard stuff and something I see happening in one form or another in most code bases I encounter.
Dependency Inversion
Dependency Injection is closely related to the dependency inversion principle (the D of SOLID). This principle states two things:
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
Now, this is a principle I don’t see widely applied. Instead, I usually see something like this:
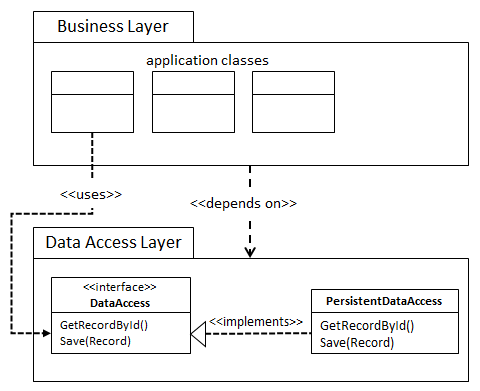
Here, we have the business layer depending on the data access code in the data access layer. When using Entity Framework code first on .NET, for example, we would have PersistentDataAccess being the class deriving from DbContext (maybe MyDomainDbContext) and from that we would extract an interface like IMyDomainDbContext representing the DataAccess interface.
This is a clear violation of the dependency inversion principle: in this case the high-level module is the module where the business logic lives (i.e. the business layer) and the low-level module is the module containing the data access code (i.e. the data layer). Adhering to the principle means that our business logic layer should not depend on our data access layer, which it does.
How does this cause us problems?
1. The data layer cannot access our domain classes
Since the business layer depends on the data layer we cannot access types from our business layer without creating circular dependency chains. While some environments actually allow those (and some don’t), in general it’s not considered particularly healthy if there are (a lot of) dependency cycles across modules.
But generally, I do want to be able to create and use types from my business layer in the data layer. For example, in DDD I want to return Domain Entities or Value objects from my DAL. Since those classes are defined in the domain layer, it is impossible to access those types in the DAL. So instead we end up with something like this:
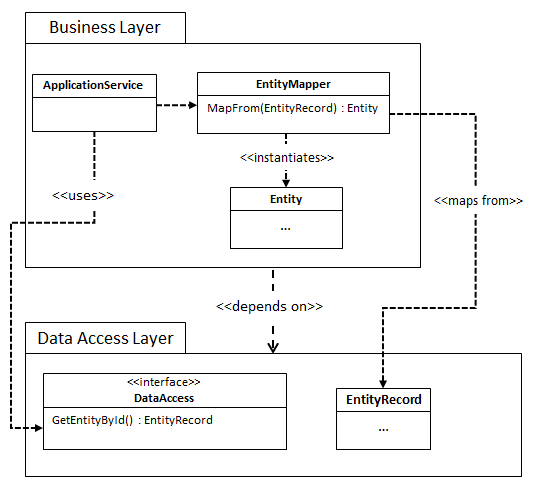
As you can see, in general, I won’t be able to use any custom business types in the DAL, including the simplest of value objects. This means all the mapping needs to happen in the business layer, which means we need to change the business layer whenever we add a new way of mapping.
By reversing the dependency, we can move all the mapping code to the DAL, keeping our business layer clutter-free and allowing the data layer to change independently:
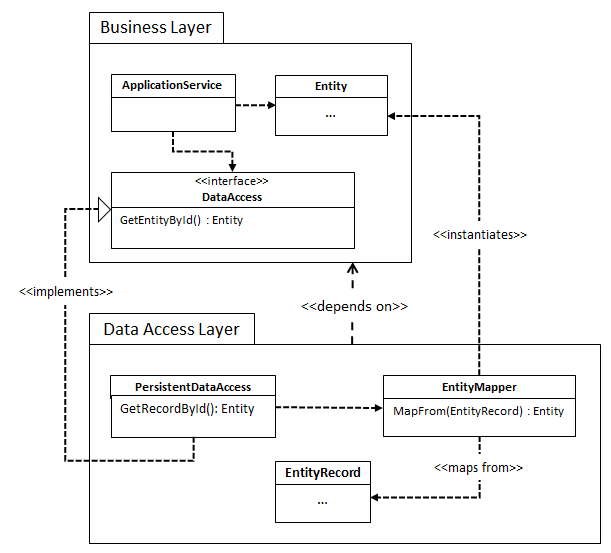
This is the heart of the dependency inversion principle. Note that we moved the definition of the DataAccess interface from the DAL to the business layer. This is another key principle: we let consumers define the interface, and leave it up to others conform to this interface.
2. It’s hard to keep your business layer clean
As you can see in the previous section, when we have the dependency pointing the wrong way, our business layer gets polluted with all kind of stuff that doesn’t really belong there, like the mapping code above. This makes the business layer harder to reason about, since we can’t do it in isolation anymore. This hurts productivity and new entrants to your code base need more time to get going.
3. All implementations depend on our data layer
Let’s say we’re writing tests for our business layer. We’ll end up with something like this:
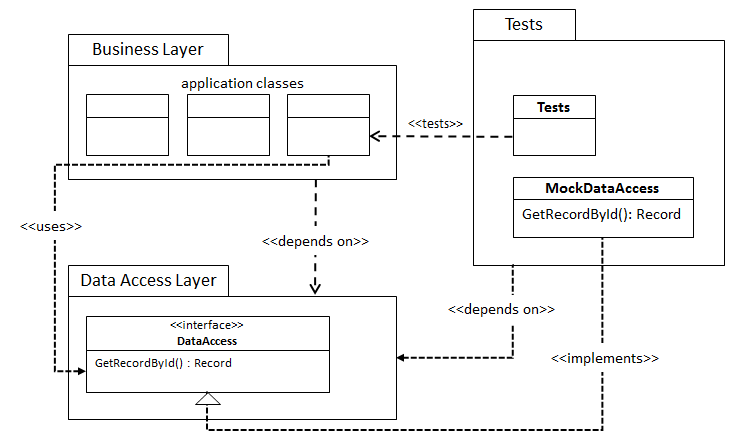
In this diagram we see that our Tests package depends on the DAL and that means that, since dependencies are transitive, our Tests package depends on everything the DAL depends on. This will usually mean that our Tests package gets to depend on the implementation chosen in the DAL layer. So if our production implementation of DataAccess is backed by something like Entity Framework, we also need to take in that dependency in the Tests package. Since we’re probably not using anything from Entity Framework for our tests, being forced to take this dependency doesn’t really feel right.
It’s even worse if we’d like to switch to a completely different DAL implementation (which, agreed, doesn’t happen as much as we’re led to believe). But let’s say we’re writing a new DAL based on NHibernate instead of the current Entity Framework. Changing ORMs is something I have actually seen happen. In this case our NHibernate implementation will have a dependency on Entity Framework. It’s pretty obvious that just cannot be right.
As before, we can solve this problem by moving DataAccess to the business layer:
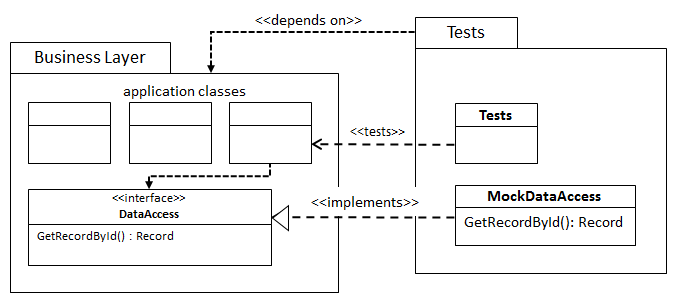
Here we’ve dropped the dependency, and the design is much simpler than the one before.
4. The data layer can force changes to the business layer
To see how this is possible, let’s again consider this situation:
If we now change a mapped property of our EntityRecord class, this will break our EntityMapper, which lives in the business layer. This is obviously something we shouldn’t want, since an implementation detail of a low-level component (data access) can now break, and therefore force a change to, a high-level component (business). In general, we just don’t want something as low-level as data access changing the most important part of our software, that is, the business.
Conclusion
In this post I’ve shown some problems that can occur when you’re applying dependency injection without also taking into account dependency inversion. In my experience these problems can become pretty big the further you get into a project.
Therefore, next time you’re using dependency injection, please also consider the direction of your dependencies and put them in a direction where low-level components depend on the high-level ones. It will save you a lot of trouble later on.
Disclaimer: In this post I mostly focused on the situation of business apps, which I’m most familiar with. I am, however, pretty sure these principles apply in other contexts as well.