Command Query Responsibility Segregation (CQRS) is one of the concepts the profoundly changed the way I develop software. Unfortunately most of the information available online conflates CQRS with event sourcing (ES) and asynchronous read-model population (introducing eventual consistency). While those 2 techniques can be very useful, they are actually orthogonal concerns to CQRS. In this post I’ll focus on the essence of CQRS, and why it helps creating more maintainable, simpler software.
A little history
In 2012 I was working on a project that had some fairly involved business logic, so we tried applying DDD to control the complexity. All started out fairly well, and we actually created a pretty rich, well-factored model that handled all the incoming transactions in a way that reflected how the business actually thought about solving the problem.
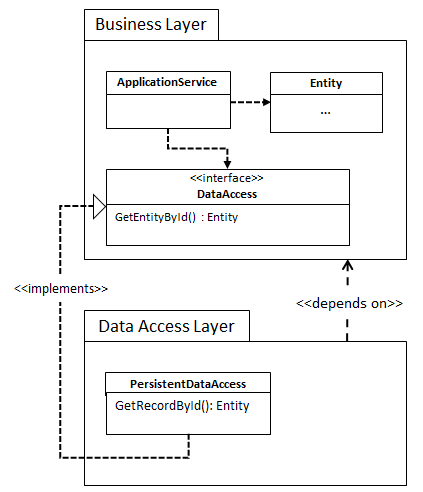
There was just one problem with our solution: the (entity) classes in our domain model were littered with public get methods. Now, those getters weren’t used to make decisions in other objects (which would break encapsulation), but were only there for displaying purposes. So whenever I need to display an entity on a page, I would fetch the entity from a repository and use the model’s get methods to populate the page with data (maybe via some DTO/ViewModel mapping ceremony).
While I think getters on entities are a smell in general, if the team has enough discipline to not use the getters to make any business decisions, this could actually be workable. There were, however, bigger problems. In a lot of scenario’s we needed to display information from different aggregates on one page: let’s say we have Customer and Order aggregates and want to display a screen with information about customers and their orders. We were now forced to include an Orders property on the Customer, like this:
From now on, whenever we were retrieving a Customer entity from the database we needed to decide whether we also needed to populate the Orders property. You can imagine that things get more complex as you increase the amount of ‘joins’, or when we just needed a subset of information, like just the order count for a given customer. Rather quickly, our carefully crafted model, made for processing transactions, got hidden by an innumerable amount of properties and its supporting code for populating those properties when necessary. Do I even need to mention what this meant for the adaptability of our model?
The worse thing was, I had actually seen this problem grind other projects to a halt before, but hadn’t acted on it back then, and I almost hadn’t this time. I thought it was just the way things were done™. But this time, I wasn’t satisfied and I thought I’d do a little googling and see if other people are experiencing the same problem.
Enter CQRS
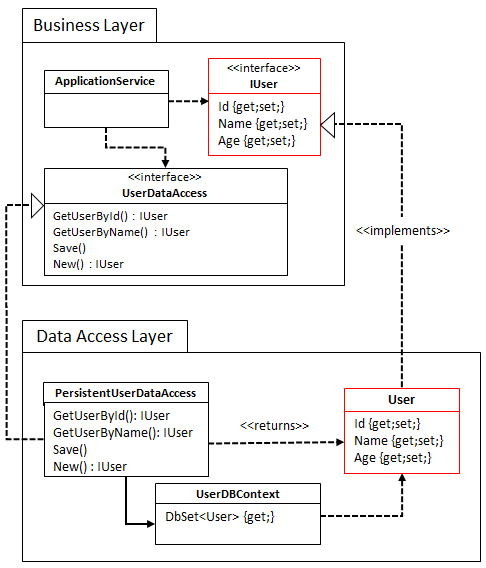
I ended up finding a thing or two about a concept called Command Query Responsibility Seggregation, or CQRS. The basic premise of CQRS is that you shouldn’t be using the code that does the reading to also do the writing. The basic idea is that a model optimized for handling transactions (writing) cannot by simultaneously be good at handling reads, and vice versa. This idea is true for both performance AND code structure. Instead, we should treat reading and writing as separate responsibilities, and reflect that in the way we design our solution:
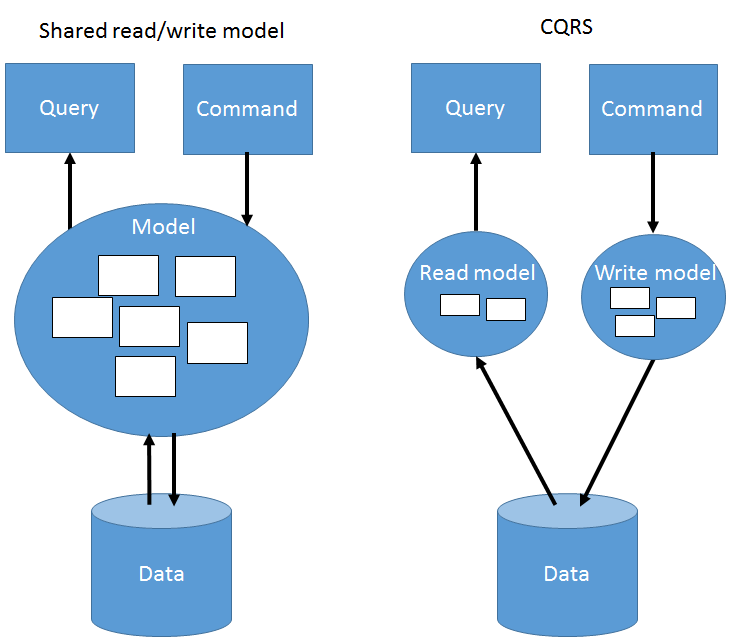
By applying this separation we can design both of them in a way that’s optimal for fulfilling their specific responsibility.
In most of the domains I’ve worked in, the complexity lies in the transaction-handling part of our system: there are complex business rules that determine the outcome of a given command. Those rules benefit from a rich domain model, so we should choose that for our write side.
On the read side, things in these systems are much simpler and usually just involve gathering some data and assembling that together into a view. For that, we don’t need a full-fledged domain model, but we can probably directly map our database to DTO’s/ViewModels and then send them to the view/client. We can easily accommodate new views by just introducing new queries and mappings, and we don’t need to change anything on our command-processing side of things.
I’ve recently worked on a project that actually had all the complexity on the read side, by the way. In that case the structure is actually inverted. I’ll try to blog about that soon.
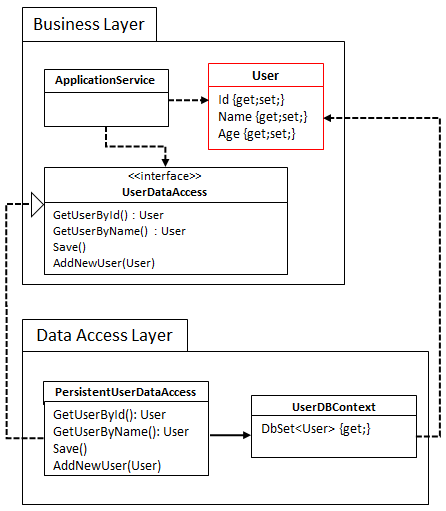
Note that in the above description, the data model is shared between the read and write model. This is not a strict necessity and, in fact, CQRS naturally allows you to also create separate data models. You would typically do that for performance reasons, which is not the focus of this post.
But what if I change the data model!?
Obviously, in the above description both the read and write model are tightly coupled to the data model, so if we change something in the data model we’ll need changes on both sides. This is true, but in my experience this has not yet been a big problem. I think this is due to a couple of reasons:
- Most changes are actually additions on the write side. This usually means reading code keeps working as it is.
- There is conceptual coupling between the read and write side anyway. In a lot of cases, if we add something on the write side, it’s of interest to the user, and we need to display it somewhere anyway.
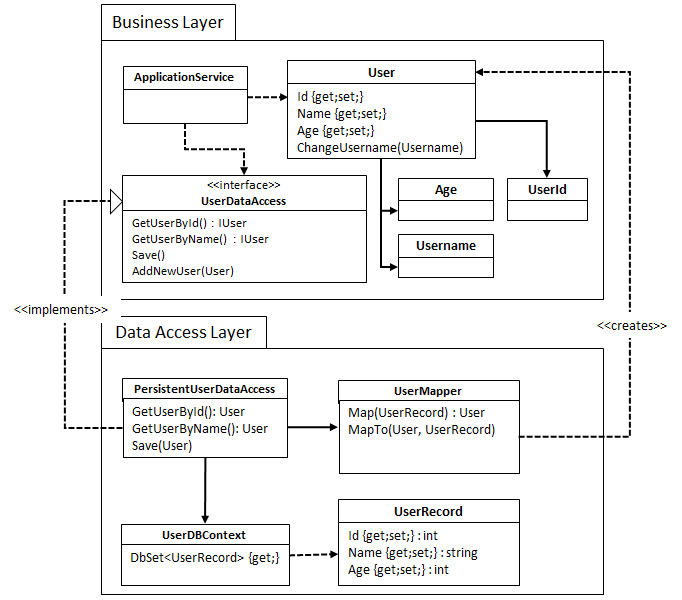
The above isn’t true if you’re refactoring your data model for technical reasons. In this case, it might make sense to create a separate data model for reading and writing.
Conclusion
For me, the idea of CQRS was mind-blowing since everyone I ever worked with, ever talked with or read a book from used the same model to do reading and writing. I had simply not considered splitting the two. Now that I do, it helps me create better focused models on both sides, and I consider my designs to be more clear and thereby maintainable and adaptable.
The value in CQRS for me is mostly in the fact that I can use it to create cleaner software. It’s one of the examples where you can see that the Single Responsibility Principle really matters. I know a lot of people also use it for more technical reasons, specifically that things can be made more performant, but for me that’s just a happy coincidence.
Acknowledgements
Greg Young is the guy that first coined CQRS, and since I learned a lot of stuff on CQRS from his work it would be strange not to acknowledge that in this post. The same goes for Udi Dahan. So if you’re reading this and like to know more (and probably better explained), please check out their blogs.